
时间:2024-12-23 05:30:04
必一体育:ARM Cortex-A78、Cortex-X1、
来源:必一体育下载 作者:必一体育app架构(准确说是IP,又称内核授权),刚刚量产的天玑1000+就是首款同时采用上述IP组合的旗舰级
ARM正式发布了下一代IP,由Cortex-X1、Cortex-A78和Mali-G78组成的“三剑客”,从即将在今年9月发布的麒麟1000开始,未来的5G SoC都将因它们而获益,并有望进一步拉近与同期苹果A系列SoC的性能差距。
目前,骁龙865、天玑1000和Exyno 980等5G SoC都拿Cortex-A77架构作为CPU中的“大核”,也因此获得了强悍的运算动力。
作为Cortex-A77的人,Cortex-A78其实并没有什么本质上的变化,Cortex-A76、A77、A78都采用了相同的Austin微架构,三代核心在设计上存在很多共性。
用ARM的话来说,就是芯片供应商(如高通联发科等)在构建核心时可以非常容易地升级SoC的IP设计,不会花费太多经历和成本,从而缩短了开发周期。
因此,大家不要对Cortex-A78性能抱有太大期待,ARM官方数据显示,A78相较于A77,其IPC(架构性能)只提升了7%,功耗降低了4%,内核小了5%,四核簇面积的缩小了15%。
现在SoC内单个“大核”在满载时的功耗约为1W,此时7nm工艺生产的Cortex-A77可以跑到2.6GHz,而5nm工艺生产的Cortex-A78则可达到3GHz,相当于在相同功耗下获得了20%的性能提升。

说实话,ARM的这种计算方式令人头大,不合理也不公平。如果Cortex-A77也用5nm工艺生产,性能也会比7nm工艺时提升不少,功耗也会明显下降。
反之,如果用7nm工艺生产Cortex-A78,其性能和功耗表现也不见得比Cortex-A77好多少。
从iPhone 5开始,苹果A系列处理器就开始了“自研”之旅,而这也是为什么每一代iPhone的性能几乎都可以领先同期Android手机圈的所有处理器。
所谓的“自研”,就是购买ARM最高级的指令集授权,然后根据自身需要开发兼容ARM的架构,能领先ARM公版的Cortex-A架构多少全看芯片商的技术水平。

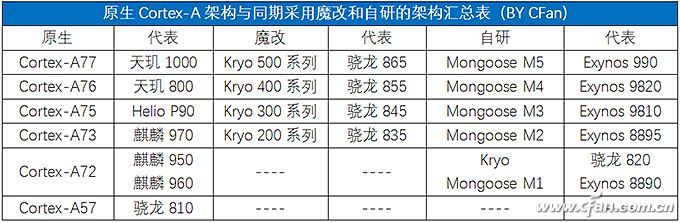
高通曾在骁龙600/800时代采用过自研的Krait架构,距离最新的骁龙820也是自研的Kyro。只是,高通发现自研架构的能耗比很难领先公版Cortex-A架构太多,不经济,所以从骁龙835开始就采取了BoC战略,也就是咱们常说的“魔改”,基于现有的公版Cortex-A架构进行版定制化。
华为从麒麟980开始,也采用了类似的思路,其大核也是基于Cortex-A架构进行了“based”,同样是一种魔改。需要注意的是,公版Cortex-A架构可以进行“魔改”的地方并不多,大家基本都是拿缓存部分开刀,所以无论是高通还是麒麟,其魔改后的内核与公版架构之间的性能差异并不大,关键还是看主频。
三星从Exynos 8890开始也加入到自研大军,并推出了名为猫鼬(Mongoose)的架构核心。但是,经过四代自主研发后,三星在2019年底已经决定放弃自研的Mongoose内核,并解散了位于德州奥斯汀的整个研发团队,未来将全面使用ARM的设计方案。
好消息是,ARM此次发布的“三剑客”中的Cortex-X1,其实就是一种允许芯片商在其上进行高度定制的IP内核,可以完全取代辛苦的“自研”之路。
基于以上的改进,Cortex-X1较之上一代A77,其单核性能可提升30%、AI性能更是大涨100%。
按照ARM的规划,未来Cortex-X1将扮演旗舰级5G SoC内的“超大核”,而Cortex-A78则属于普通的“大核”,再与Cortex-A55构成“1+3+4”的三丛集DynamIQ集群,以实现性能和功耗的完美平衡。
唯一可惜的,就是Cortex-X1内核会占用更大的封装面积。ARM的资料显示,4个Cortex-A78核心在搭配4MB L3缓存时,其性能比前代A77可提升20%,同时核心面积降低15%;而1个Cortex-X1+3个Cortex-A78在搭配8MB L3缓存时,虽然核心面积会增加15%,但峰值性能提升了30%。
在Android领域,ARM公版的Mali系列GPU已经一枝独秀,昔日的老对手PowerVR已被边缘化。而新一代Mali-G78 GPU的问世,将进一步巩固ARM的亲儿子在GPU领域的领先地位。
也许是没有太大的竞争压力,所以Mali-G78依旧沿用了Mali-G77采用的Valhall图形架构,但它对全局时钟域进行了优化,改为全新的两级结构,实现了上层共享GPU模块与实际着色器核心频率的分离,也就是异步时钟域。这样一来,GPU的核心可以工作在与其他部分不同的频率上,可快可慢,从而解决几何输出与计算、纹理、引擎之间的不平衡问题,还能让GPU运行在不同电压上,从而降低功耗、提高能效,这也是桌面级CPU、GPU通用的做法。
此外,Mali-G78还彻底重写了FMA(融合乘加)引擎,包括新的乘法架构、新的加法架构、FP32/FP16浮点,可以节省30%的功耗。
这一次,Mali-G78最多可以武装24个计算单元,较之前辈增加了50%。但正如上面的原因,哪怕搭配最新的5nm工艺,估计实际商用的最大规模也就是16个左右,再多手机散热就压不住了。
根据ARM的资料显示,得益于综合架构、工艺等各方面的改进,Mali-G78相比于Mali-G77的性能提升幅度可达25%,即便是在同等工艺条件下也可提升15%, 同时能效提升10%,机器学习性能提升15%。
此外,ARM还新推出了Mali-G68 GPU,用于填补Mali-G7系列和Mali-G5系之间的空白。从现有的资料来看,Mali-G68的架构和参数和Mali-G78一模一样,只是最多仅能搭配6个计算单元。
即将在9月份发布的麒麟1000系列应该是首发Cortex-A78和Mali-G78的5G SoC,但它能否用上Cortex-X1架构还不得而知。而明年上市的骁龙875、天玑2000和Exyno 1000系列也将用上“三剑客”中的至少1个成员,至于它们实际性能较之现有的旗舰能有多少提升,就让我们拭目以待吧。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。举报投诉armarm+关注
Streamline评测模板中的GPU性能计数器,该模板是Valhall架构系列的一部分。 Streamline中的计数器模板遵循循序渐进的分析工作流
Streamline评测模板中的马里性能计数器,该模板是Valhall架构系列的一部分。 Streamline中的计数器模板遵循循序渐进的分析工作流
内核。 它提供参考文档并包含寄存器的编程详细信息。 它还描述了内存系统、缓存、中断和调试功能。
即将推出新一代的旗舰CPU、GPU和NPU /
来自技巧专家Ice Universe的新信息讨论了Exynos 2100和Snapdragon 875的图形性能是否相等。他指出,Exynos 2100将配备具有14个图形内核的
星宣称,Exynos 1080的单核性能相比前代提升了1.5倍,多核性能提升了2倍。 Exynos 1080还首发了